# 持久化机制
## 背景
场景问题:服务器断电重启,未被消费的消息是否会在重启之后被继续消费? 两种选择:非持久性模式/持久性模式
**非持久性模式:**
`服务器断电(关闭)之后,使用非持久性模式时,没有被消费的消息不会继续消费全部丢失;` 程序会报一个连接关闭异常停止运行,继续启动服务器运行程序,不会接收任何消息。
**持久性模式:**
`服务器断电(关闭)后,使用持久性模式时,没有被消费的消息会继续消费;` 程序也会报连接关闭异常,但再次启动服务器和程序后,接收方还能继续原来的消息再次接收。
## ActiveMQ的几种存储模式选择
* AMQ消息存储 (默认的消息存储)
* KahaDB 消息存储(提供容量的提升和恢复能力) 基于文件支持事务的消息存储器,是一个可靠,高性能,可扩展的消息存储器
* JDBC 消息存储(消息基于JDBC存储)
* 使用Mysql或Oracle数据库存储消息
* Memory 消息存储(基于内容的消息存储) ActiveMQ支持将消息保存到内存中,将Broker的“prsistent” 属性设置为“false”。
## 持久化操作
* **持久化文件**
ActiveMQ默认就支持这种方式,只要在发消息时设置消息为持久化就可以了。
打开安装目录下的配置文件:
D:\ActiveMQ\apache-activemq\conf\activemq.xml在越80行会发现默认的配置项:
\
\
\
注意这里使用的是kahaDB,是一个基于文件支持事务的消息存储器,是一个可靠,高性能,可扩展的消息存储器。
```
他的设计初衷就是使用简单并尽可能的快。KahaDB的索引使用一个transaction log,并且所有的destination只使用一个index,有人测试表明:如果用于生产环境,支持1万个active connection,每个connection有一个独立的queue。该表现已经足矣应付大部分的需求。
```
然后再发送消息的时候改变第二个参数为:
MsgDeliveryMode.Persistent
Message保存方式有2种\
PERSISTENT:保存到磁盘,consumer消费之后,message被删除。\
NON\_PERSISTENT:保存到内存,消费之后message被清除。\
注意:堆积的消息太多可能导致内存溢出。
然后打开生产者端发送一个消息:
[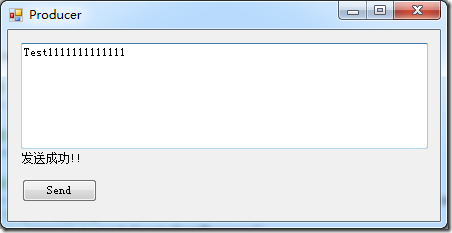](https://images0.cnblogs.com/blog/16765/201411/272212014189293.png)
不启动消费者端,同时在管理界面查看:
[](https://images0.cnblogs.com/blog/16765/201411/272212022316879.png)
发现有一个消息正在等待,这时如果没有持久化,ActiveMQ宕机后重启这个消息就是丢失,而我们现在修改为文件持久化,重启ActiveMQ后消费者仍然能够收到这个消息。
[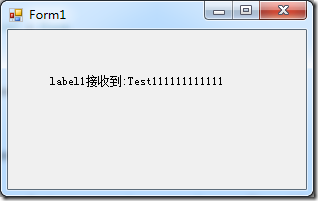](https://images0.cnblogs.com/blog/16765/201411/272212029963778.png)
* **持久化为数据库**
我们从支持Mysql为例,将:
* commons-dbcp-1.4.jar
* commons-pool-1.6.jar
* mysql-connector-java-5.1.30.jar
D:\ActiveMQ\apache-activemq\lib目录下。
打开并修改配置文件:
```
file:${activemq.conf}/credentials.properties
```
启动ActiveMQ,分析数据表结构发现多了3张表:
**activemq\_acks、activemq\_lock、activemq\_msgs**
> **activemq\_acks:**用于存储订阅关系。如果是持久化Topic,订阅者和服务器的订阅关系在这个表保存。
>
> CONTAINER:消息的目的地\
> SUB\_DEST:如果是使用static集群,这个字段会有集群其他系统的信息\
> CLIENT\_ID:每个订阅者客户端ID\
> SUB\_NAME:订阅者名称\
> SELECTOR:选择器,可以选择只消费满足条件的消息。条件可以用自定义属性实现,可支持多属性and和or操作\
> LAST\_ACKED\_ID:记录消费过的消息的id。\
> PRIORITY:优先级\
> XID:\
> **activemq\_lock**:用于记录哪一个Broker是Master Broker。这张表只有在集群环境中才会用到,在集群中,只能有一个Broker来接收消息,那么这个Broker就是主Broker,其他的作为从Broker,用来备份等待。
>
> ID:主键
>
> TIME:时间
>
> BROKER\_NAME:Broker名称
>
> **activemq\_msgs**:用于存储消息,Topic和Queue消息都会保存在这张表中
>
> ID:自增主键\
> CONTAINER:容器名称\
> MSGID\_PROD:消息发送者客户端的主键\
> MSGID\_SEQ:发送消息的顺序,msgid\_prod+msg\_seq可以组成jms的messageid\
> EXPIRATION:消息的过期时间,存储的是从1970-01-01到现在的毫秒数\
> MSG:消息本体的java序列化对象的二进制数据\
> PRIORITY:优先级,从0-9,数值越大优先级越高
然后分别启动生产者和消费者,在MySQL中进行消息数据查看。
* **KahaDB方式**
KahaDB是从ActiveMQ 5.4开始默认的持久化插件,也是我们项目现在使用的持久化方式。
KahaDb恢复时间远远小于其前身AMQ并且使用更少的数据文件,所以可以完全代替AMQ。\
kahaDB的持久化机制同样是基于日志文件,索引和缓存。
配置方式:
```
```
> d irectory : 指定持久化消息的存储目录
>
> journalMaxFileLength : 指定保存消息的日志文件大小,具体根据你的实际应用配置
**(1)KahaDB主要特性**\
1、日志形式存储消息;\
2、消息索引以B-Tree结构存储,可以快速更新;\
3、完全支持JMS事务;\
4、支持多种恢复机制;
**(2)KahaDB的结构**
消息存储在基于文件的数据日志中。如果消息发送成功,变标记为可删除的。系统会周期性的清除或者归档日志文件。\
消息文件的位置索引存储在内存中,这样能快速定位到。定期将内存中的消息索引保存到metadata store中,避免大量消息未发送时,消息索引占用过多内存空间。

**Data logs:**\
Data logs用于存储消息日志,消息的全部内容都在Data logs中。\
同AMQ一样,一个Data logs文件大小超过规定的最大值,会新建一个文件。同样是文件尾部追加,写入性能很快。\
每个消息在Data logs中有计数引用,所以当一个文件里所有的消息都不需要了,系统会自动删除文件或放入归档文件夹。
**Metadata cache :**\
缓存用于存放在线消费者的消息。如果消费者已经快速的消费完成,那么这些消息就不需要再写入磁盘了。\
Btree索引会根据MessageID创建索引,用于快速的查找消息。这个索引同样维护持久化订阅者与Destination的关系,以及每个消费者消费消息的指针。
**Metadata store**\
在db.data文件中保存消息日志中消息的元数据,也是以B-Tree结构存储的,定时从Metadata cache更新数据。Metadata store中也会备份一些在消息日志中存在的信息,这样可以让Broker实例快速启动。\
即便metadata store文件被破坏或者误删除了。broker可以读取Data logs恢复过来,只是速度会相对较慢些。
* **LevelDB方式**
从ActiveMQ 5.6版本之后,又推出了LevelDB的持久化引擎。
目前默认的持久化方式仍然是KahaDB,不过LevelDB持久化性能高于KahaDB,可能是以后的趋势。
在ActiveMQ 5.9版本提供了基于LevelDB和Zookeeper的数据复制方式,用于Master-slave方式的首选数据复制方案。
* **AMQ方式**
性能高于JDBC,写入消息时,会将消息写入日志文件,由于是顺序追加写,性能很高。为了提升性能,创建消息主键索引,并且提供缓存机制,进一步提升性能。每个日志文件的大小都是有限制的(默认32m,可自行配置)。\
当超过这个大小,系统会重新建立一个文件。当所有的消息都消费完成,系统会删除这个文件或者归档(取决于配置)。\
主要的缺点是AMQ Message会为每一个Destination创建一个索引,如果使用了大量的Queue,索引文件的大小会占用很多磁盘空间。而且由于索引巨大,一旦Broker崩溃,重建索引的速度会非常慢。
配置片段如下:
```
```
虽然AMQ性能略高于Kaha DB方式,但是由于其重建索引时间过长,而且索引文件占用磁盘空间过大,所以已经不推荐使用。
## 参考文档:
---
# Agent Instructions: Querying This Documentation
If you need additional information that is not directly available in this page, you can query the documentation dynamically by asking a question.
Perform an HTTP GET request on the current page URL with the `ask` query parameter:
```
GET https://tuonioooo-notebook.gitbook.io/high-concurrent-queue/activemq/chi-jiu-hua-ji-zhi.md?ask=
```
The question should be specific, self-contained, and written in natural language.
The response will contain a direct answer to the question and relevant excerpts and sources from the documentation.
Use this mechanism when the answer is not explicitly present in the current page, you need clarification or additional context, or you want to retrieve related documentation sections.